
Probing LeWM: What Does a JEPA World Model Actually Learn?
Published:
LeWM is a latent world model for robot manipulation trained with a JEPA objective. It encodes visual observations with a ViT, then learns a transformer predictor that forecasts future latent states conditioned on actions — without decoding back to pixels.
The paper shows strong downstream performance, but I was curious about what the model actually learns internally. I wrote three diagnostic scripts and one ablation to probe it on the PushT task. The results are mixed in an interesting way.
All code is on GitHub.
1. Latent Space Structure
The first question is basic: does the encoder build a semantically organised latent space, or is it just a compressed pixel hash?
I encoded 20 expert trajectories and projected all timestep embeddings down to 2D with PCA, colouring each point by its normalised position within the episode (purple = early, yellow = late).
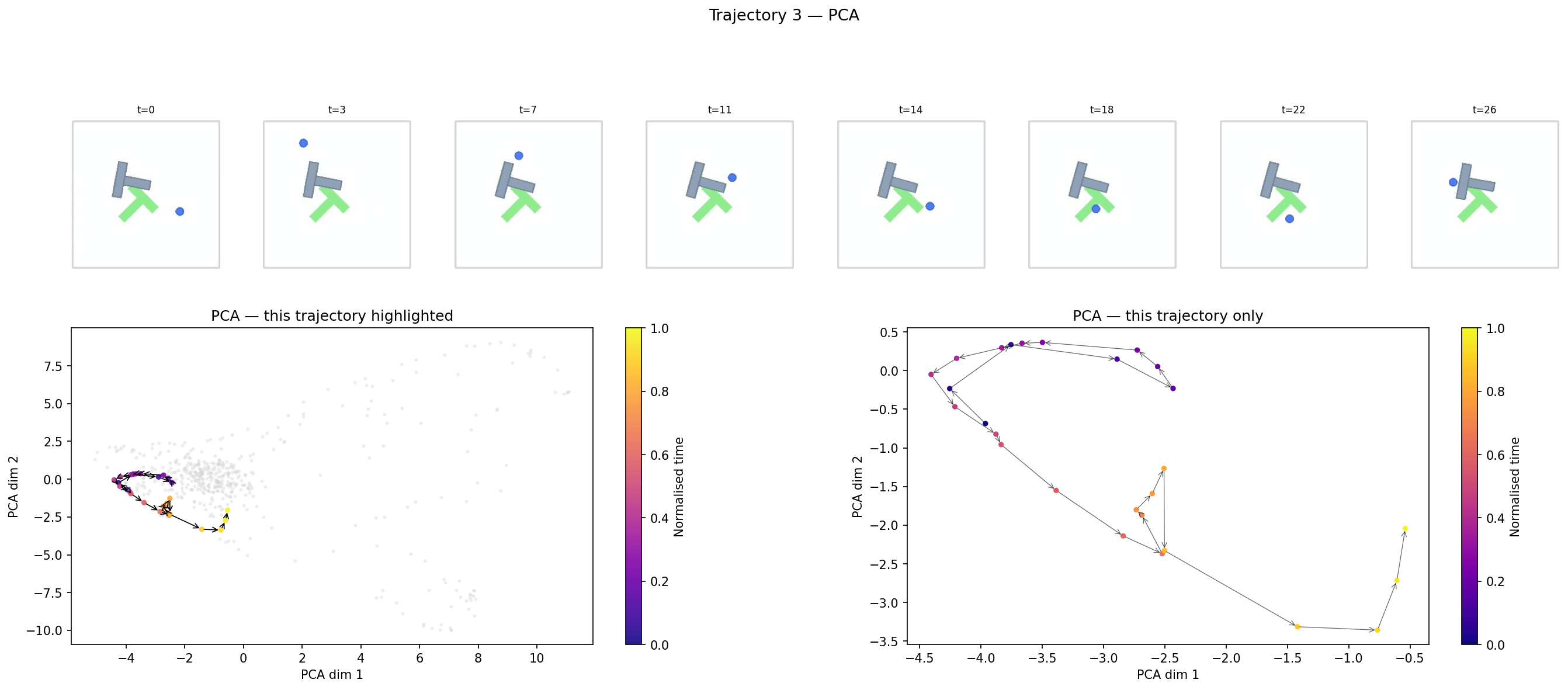
The filmstrip at the top shows the actual frames. The bottom-left panel shows this trajectory highlighted against all others (grey). The bottom-right panel isolates its path through PCA space.
What this shows: trajectories form distinct, spatially separated clusters with a consistent temporal gradient inside each cluster. The encoder is not just compressing pixels — it is tracking task progression. Different episodes end up in different regions of the space, and within a single episode the embedding moves monotonically through that region as the task advances.
2. Prediction Degradation Over Horizon
LeWM’s predictor is designed to autoregressively forecast future latent states given real actions. I measured how quickly those predictions degrade as the rollout horizon grows.
Procedure: encode all frames once to get ground-truth embeddings $z_0 \ldots z_T$, then from a seeded context window predict forward $H$ steps using real actions, computing cosine distance to the ground-truth embedding at each horizon.
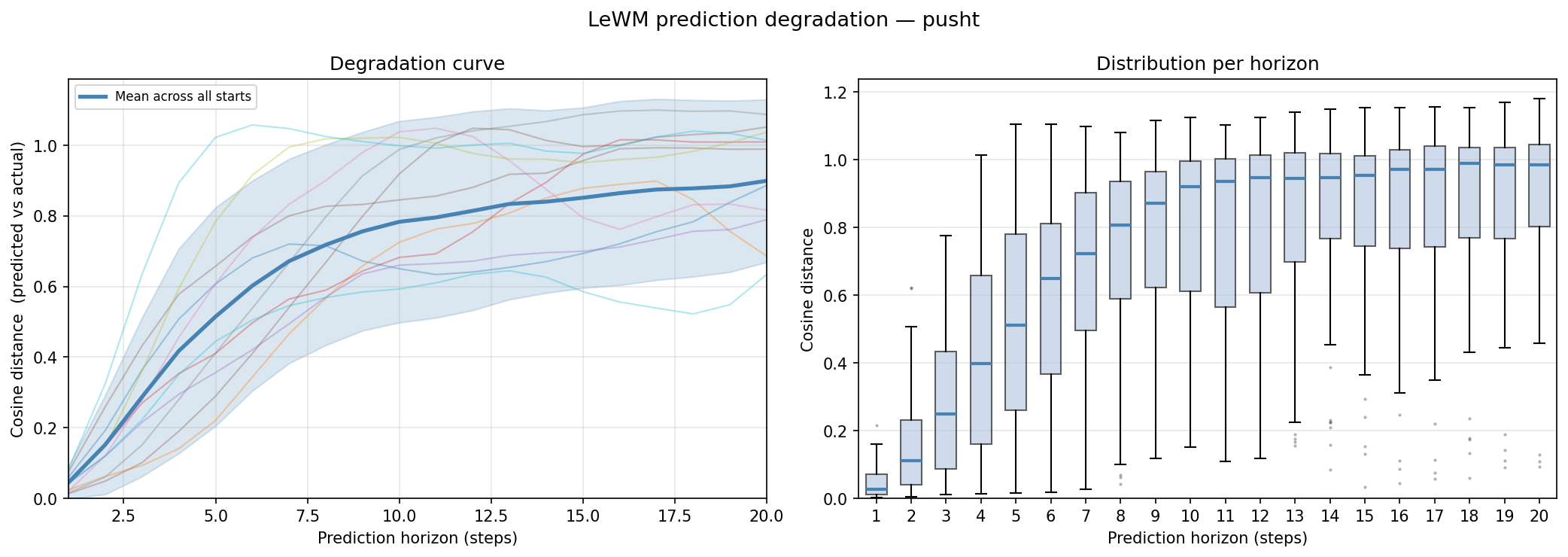
Mean cosine distance rises steeply from ~0.1 at horizon 1 to ~0.8 by step 10, where it roughly saturates. The right panel shows the full distribution per horizon — variance is large throughout. At short horizons the predicted paths stay close to the actual manifold.
Practical implication: if you were using LeWM inside a model-predictive controller, you would want to keep the planning horizon below ~5 steps to stay in the regime where predictions are meaningful.
3. Surprise Under Artifact Injection
Can the model detect when something unexpected appears in the scene? I operationalise “surprise” as one-step prediction error:
\[\text{surprise}_t = 1 - \cos(\hat{z}_t,\, z_t)\]where $\hat{z}_t$ is the predicted embedding from a context and $z_t$ is the encoding of the (possibly perturbed) frame.
I injected a red rectangle that slides horizontally across the frame starting at step 5 and exiting at step 15. Three conditions were measured:
- Baseline — clean context, clean frames
- Perturbed — clean context, perturbed frames (predictor is blind to the artifact)
- Perturbed context — perturbed context, perturbed frames (predictor sees the artifact in its history window)
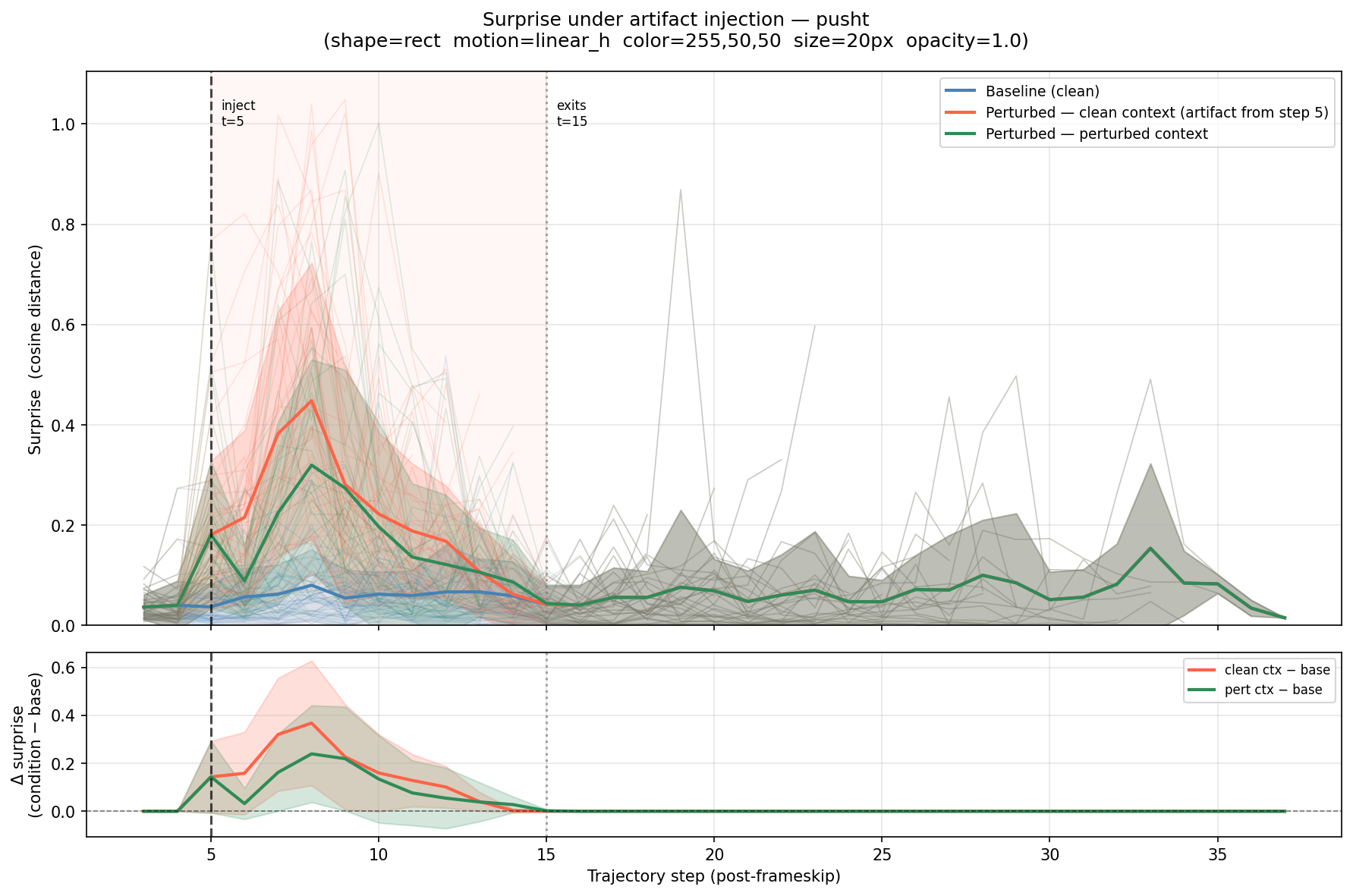
The frame comparison below shows clean (top row) vs. perturbed (bottom row):

Finding 1 — emergent anomaly detection. With a clean context (red), surprise spikes immediately at step 5, peaks around step 8–10, and returns to baseline after the artifact exits at step 15. The model was never trained to detect anomalies — the prediction error signal alone is sufficient to flag an out-of-distribution stimulus.
Finding 2 — rapid adaptation. The green curve tells a different story. When the predictor is given perturbed frames in its history window, surprise collapses to baseline quicker than the clean context (red). The predictor, having seen the artifact move across a handful of frames, substantially reduces its prediction error for subsequent perturbed frames.
This is not trivial: the artifact is entirely out-of-distribution, yet after observing it for history_size steps the predictor can extrapolate its presence well enough that the prediction error drops to near-baseline levels. The model is not just detecting the anomaly — it is adapting to it in-context.
4. Does the Predictor Actually Use Actions?
This is the most pointed question. JEPA predictors claim to be action-conditioned, but the training loss only measures whether the predictor matches the target embedding — it doesn’t force the predictor to use every input. If the embedding manifold is smooth enough, a predictor could minimise loss by temporal extrapolation alone, ignoring the action signal.
I tested this with a counterfactual experiment: run the same autoregressive rollout from the same ground-truth context under three conditions:
- Real actions — the actions that actually generated the trajectory
- Shuffled actions — actions drawn randomly from other trajectories, preserving the marginal distribution but destroying temporal alignment
- Zero actions — all zeros, the maximum ablation
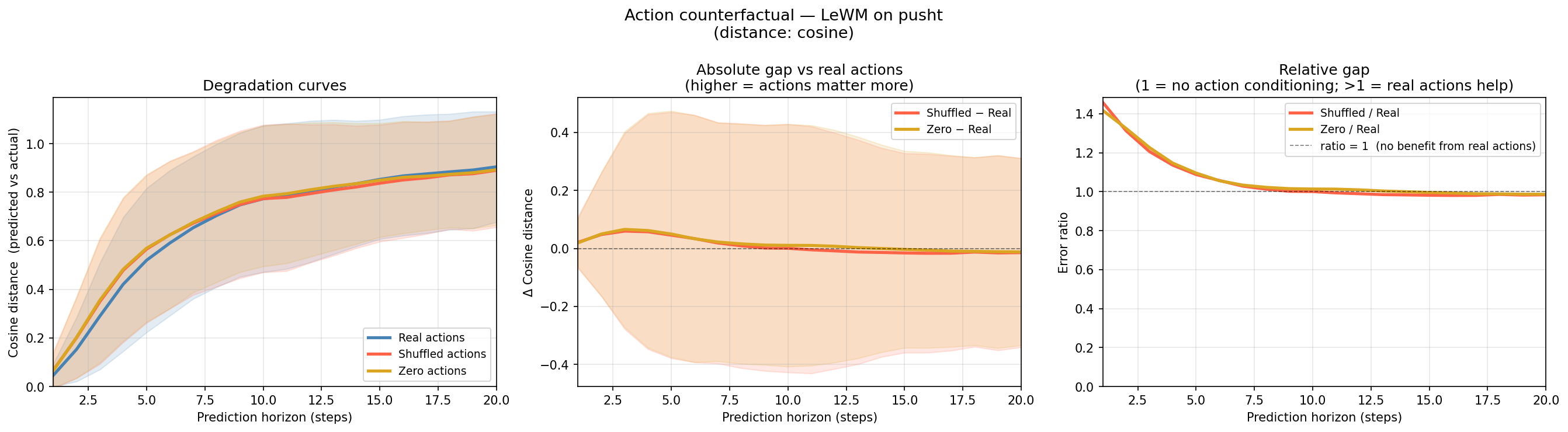
The left panel overlays the three degradation curves. The middle panel shows the absolute gap relative to real actions. The right panel shows the ratio.
The finding: real actions provide roughly 30–40% lower cosine distance at horizon 1–5. The gap closes by step 10 and is negligible beyond that. Notably, shuffled ≈ zero across all horizons — the marginal distribution of actions carries no useful signal; only the temporally correct actions matter.
This means:
- The predictor does genuinely condition on actions, but only in a short window (~5 steps)
- Beyond ~10 steps, rollouts with any action sequence converge to the same predicted future
Summary
| Probe | Finding |
|---|---|
| Latent structure | Distinct clusters per trajectory, monotonic temporal gradient |
| Prediction horizon | Cosine distance saturates ~0.8 by step 10; useful below ~5 steps |
| Surprise detection | Anomaly signal from prediction error, adapting to anomaly in-context |
| Action conditioning | Real actions help 30–40% at short horizons; negligible beyond step 10 |
The most actionable result for practitioners: LeWM’s effective planning horizon is approximately 5 steps. Short-horizon MPC can meaningfully discriminate between action sequences; longer rollouts are essentially action-invariant and dominated by temporal extrapolation.
Code for all four experiments: github.com/anthonyprinaldi/le-wm